

Home Assistant 的唤醒词方法
挑战
- 唤醒词必须被极快地处理:你不能在说出唤醒词 5 秒后,语音助手才开始聆听。
- 几乎没有容忍误触发的空间。
- 唤醒词处理依赖计算密集型 AI 模型。
- 语音卫星硬件通常算力不高,因此唤醒词引擎需要硬件专家来优化模型,才能让其顺畅运行。
实现方式
为了不受限于特定硬件,唤醒词检测会在 Home Assistant 内部完成。语音卫星设备会持续对房间中的当前音频进行采样以检测人声。当它检测到语音后,卫星会将音频发送到 Home Assistant,由 Home Assistant 判断是否说出了唤醒词,并处理其后的命令。
这意味着任何能够流式传输音频的设备都可以变成语音卫星,即使它本身没有足够性能在本地运行唤醒词检测也没关系。这也让我们的开发者社区能够尝试各种唤醒词模型,而不必为了适配低功耗语音卫星设备而压缩模型。
移动设备的例外情况:Android 手机等移动设备会通过 Home Assistant Companion App 使用 microWakeWord 进行设备端唤醒词检测。这样既能节省电池,也能确保在网络连接不稳定或不可用时唤醒词检测仍可工作。只有在检测到唤醒词后,设备才会将音频发送给 Home Assistant。更多信息请参阅 Android 上的 Assist。
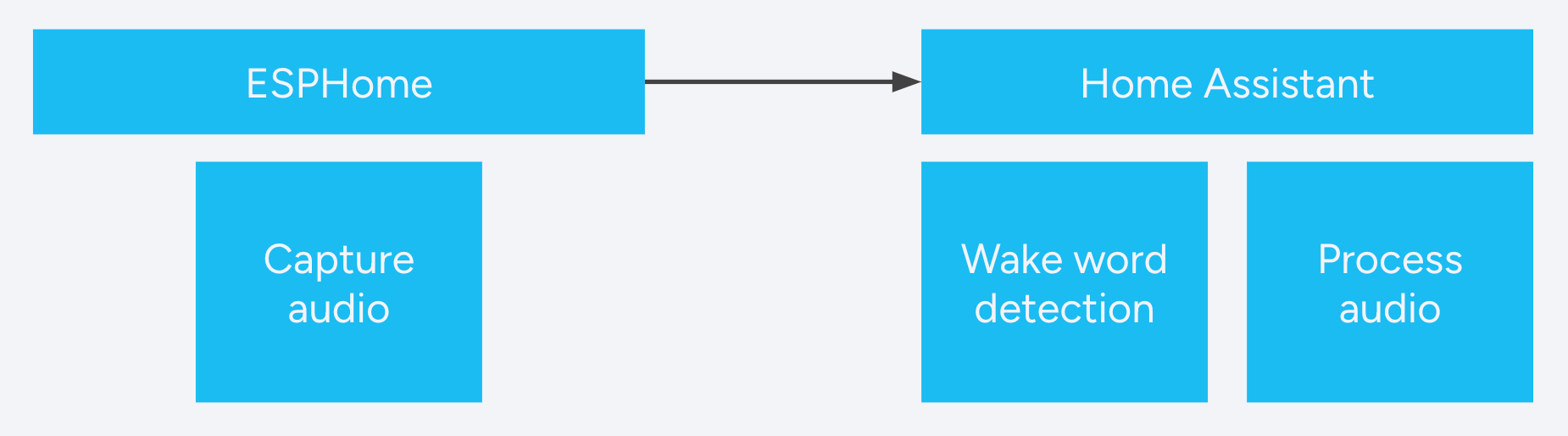 唤醒词架构概览
唤醒词架构概览
这种方式的缺点
-
不同设备采集到的音频质量不同。带有多个麦克风和音频处理芯片的免提设备能非常清晰地采集语音;而只有一个麦克风且没有后处理的设备,效果就差很多。我们会在 Home Assistant 内部通过音频后处理来弥补较差的音质,用户也可以使用更好的语音转文本模型来提升准确率,例如 Home Assistant Cloud 附带的模型。
-
每个卫星在流式传输音频时,都会持续占用 Home Assistant 的资源。目前,用户可同时让 5 个语音卫星传输音频,而不会压垮树莓派 4。为了进一步扩展规模,我们更新了 Wyoming 协议,让用户可以在外部服务器上运行唤醒词检测。
关于 openWakeWord 应用
Home Assistant 的唤醒词依赖 David Scripka 发起的新项目 openWakeWord。这个项目在真实场景中具备良好准确率,可运行在通用硬件上,而且任何人都可以训练自己的基础唤醒词模型。
 用户可以为每个已配置的语音助手选择要监听的唤醒词
用户可以为每个已配置的语音助手选择要监听的唤醒词
目标
openWakeWord 的创建围绕 4 个目标展开:
- 足够快,适合真实使用场景。
- 足够准,适合真实使用场景。
- 具备简单的模型架构和推理流程。
- 训练新模型时几乎不需要人工收集数据。
模型训练
openWakeWord 构建于一个由 Google 训练的开源音频嵌入模型之上,并使用文本转语音系统 Piper 进行微调。Piper 会为每个唤醒词生成成千上万段音频片段,模拟不同说话者的变化。随后,这些音频会被增强,使其听起来像是在不同类型的房间中、以距麦克风不同距离、用不同语速说出的。最后,这些片段还会与音乐、环境音和对话等背景噪声混合,再送入训练流程以生成唤醒词模型。
 openWakeWord 训练流程概览。
openWakeWord 训练流程概览。
支持的语言
OpenWakeWord 目前仅适用于英语唤醒词。这是因为其他语言仍然缺少覆盖大量不同说话者的模型。随着各语言可用的多说话者模型增多,也可以训练出适用于其他语言的类似模型。
Docker 中的 openWakeWord
如果你运行的不是 Home Assistant OS,openWakeWord 也可以作为 Docker 容器 使用。容器启动后,你需要添加 Wyoming 集成,并将其指向对应的 IP 地址和端口(通常是 10400)。
其他唤醒词引擎
Home Assistant 自带默认选项,但也允许用户配置语音助手的各个部分,唤醒词也不例外。
你可以将其他唤醒词引擎作为集成添加,也可以将其作为独立程序运行,并通过 Wyoming 协议 与 Home Assistant 通信。
 唤醒词如何集成到 Home Assistant 中
唤醒词如何集成到 Home Assistant 中
例如,我们也提供 Porcupine (v1) 唤醒词引擎。它支持英语、法语、西班牙语和德语中的 29 个唤醒词,包括 Computer、Framboise、Manzana 和 Stachelschwein。
关于设备端唤醒词处理(microWakeWord)
由 Kevin Ahrendt 创建的 microWakeWord 让 ESP32-S3-BOX-3、Android 手机等设备可以进行设备端唤醒词检测。
由于 openWakeWord 对于 S3-BOX-3 这类低功耗设备来说过于庞大,因此它的唤醒词检测会在 Home Assistant 服务器上运行。
将唤醒词检测放在 Home Assistant 上执行后,像 M5 ATOM Echo Development Kit 这样的低功耗设备只需传输音频,其余处理都在别处完成。 缺点是,增加更多语音助手会让 Home Assistant 占用更多 CPU,同时也会增加网络流量。
这时就轮到 microWakeWord 出场了;它是一个基于 Google's Inception neural network 的更轻量模型。由于这个新模型体积更小,因此它可以运行在带有 ESP32 芯片的低功耗设备上,例如 S3-BOX-3 内部的 ESP32-S3 芯片,也可以运行在 Android 手机上。(对于 ESPHome 设备,它也支持现已停产的 S3-BOX 和 S3-BOX-Lite)。
目前已有 三个模型 为 microWakeWord 训练完成:
- okay nabu
- hey jarvis
- alexa
试试看!
有几种简单方式可以开始使用唤醒词:
- 按照 $13 语音助手 指南操作。这个教程使用小巧的 ATOM Echo,通过 openWakeWord 检测唤醒词。
- 按照指南设置 ESP32-S3-BOX-3 语音助手。这个教程使用带显示屏、体积更大的 S3-BOX-3 设备。它既可以使用 openWakeWord 检测唤醒词,也可以使用 microWakeWord 进行设备端唤醒词检测。
- Home Assistant Android 配套应用 支持使用 microWakeWord 进行设备端唤醒词检测。即使手机处于锁定状态或应用在后台,"Hey Nabu"、"Hey Jarvis" 和 "Hey Mycroft" 等唤醒词也可以工作。